"인공지능은 인간의 뇌를 모방한 기계입니다." 과학 교양서의 도입부에서, 뉴스 기사의 헤드라인에서, 기업 IR 자료의 첫 문장에서 이 표현은 어김없이 등장합니다. 너무도 익숙한 나머지 우리는 이것이 검증된 사실인지 아니면 오랜 시간 반복을 통해 사실처럼 굳어진 이야기인지를 잘 묻지 않습니다. 그런데 지금 이 순간 전 세계 수억 명이 사용하고 있는 ChatGPT, Gemini, Claude 같은 AI는 실제로 어디서 왔을까요? 그리고 그 AI는 정말로 뇌를 닮아 있을까요?
답은 단순하지 않습니다. 그리고 바로 그 단순하지 않음 속에서, 우리 시대 기술과 자본과 인식이 서로 어떻게 얽혀 작동하는지를 읽어낼 수 있습니다.
내러티브의 기원 — 1958년, 한 심리학자의 선언
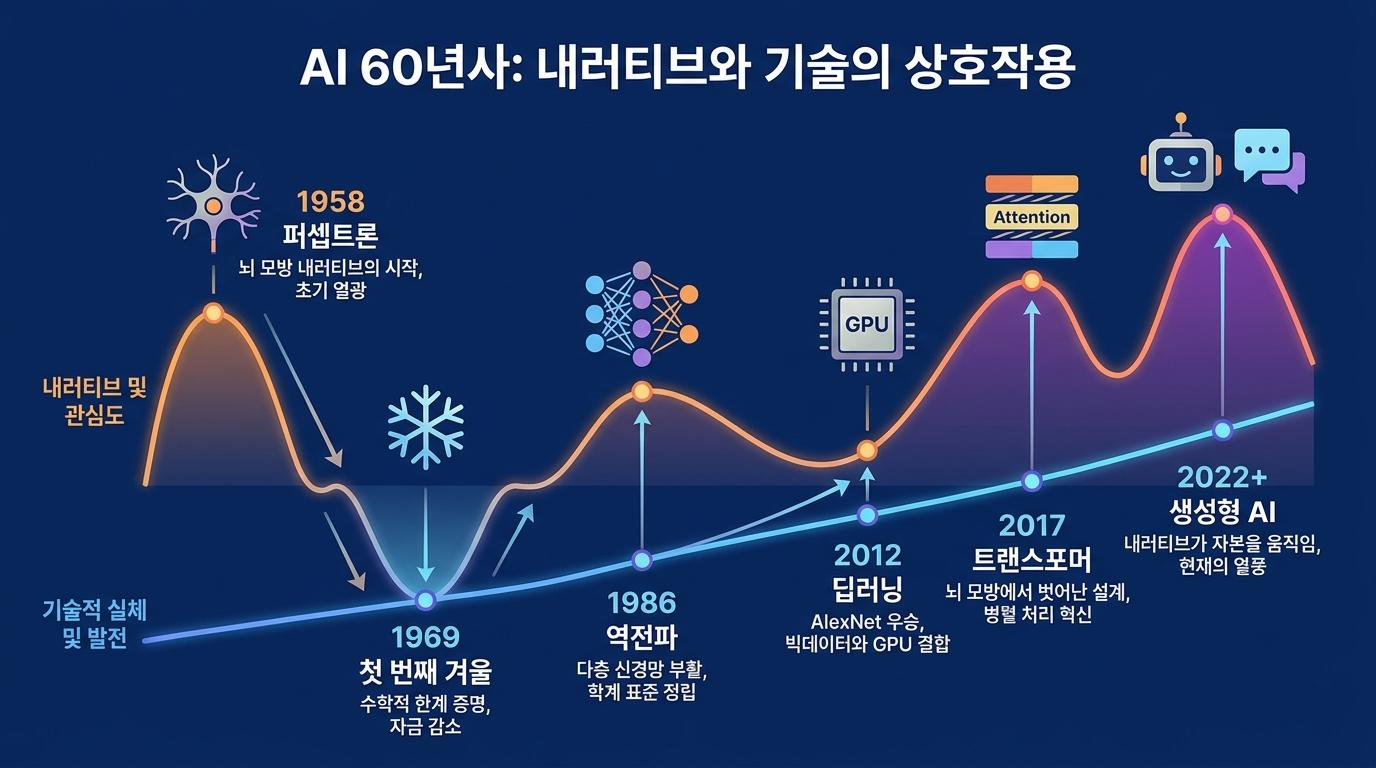
현대 AI의 출발점을 찾으려면 1958년으로 거슬러 올라가야 합니다. 미국의 심리학자 프랭크 로젠블랫(Frank Rosenblatt)은 퍼셉트론(Perceptron)이라는 모델을 발표하며 세계 최초의 학습하는 인공신경망 하드웨어를 구현했습니다. 카드 이미지를 카메라로 인식하고 약 50번의 반복 학습 끝에 스스로 분류를 해내는 이 기계는 당시로서는 경이로운 성과였습니다.
퍼셉트론은 신경세포, 즉 뉴런의 작동 방식에서 영감을 받았습니다. 다른 뉴런으로부터 신호를 받아 합산하고, 임계값을 넘으면 다음 뉴런으로 신호를 전달하는 구조를 수학적으로 단순화한 것입니다. 로젠블랫은 논문 제목에 "뇌의 정보 저장 및 조직화 모델"이라고 명시했고, 발표 이후 기자회견에서도 이 내러티브를 적극적으로 밀어붙였습니다. "AI가 결국 걷고, 말하고, 보고, 쓰게 될 것"이라는 그의 발언은 당시 SF 소설의 상상에나 가까운 것이었지만, 언론은 이를 열광적으로 받아들였습니다.
그런데 여기서 중요한 사실이 하나 있습니다. 1952년, 생리학자 호지킨(Hodgkin)과 헉슬리(Huxley)는 실제 뉴런의 작동 원리를 미분방정식으로 정밀하게 모델링했고, 이 연구는 1963년 노벨 생리의학상으로 이어졌습니다. 이 '진짜 뉴런 모델'은 이온 채널 동역학과 시간에 따른 발화 패턴을 포함한 것으로, 지금도 슈퍼컴퓨터 없이는 시뮬레이션이 어렵습니다. 퍼셉트론은 이 정밀한 생물학적 모델을 극단적으로 단순화한 것이었고, 로젠블랫은 그 단순화된 구조에 학습 알고리즘을 더하면서 뇌와의 연관성을 적극적으로 강조했습니다. 내러티브는 기술과 함께 태어난 것이 아니라, 설계된 것이었습니다.
겨울과 부활의 반복 — 내러티브가 버텨낸 시간
1969년, MIT AI 연구소의 공동 창립자이자 튜링상 수상자인 마빈 민스키(Marvin Minsky)는 저서 『퍼셉트론스(Perceptrons)』를 통해 단층 퍼셉트론이 간단한 비선형 문제조차 풀지 못한다는 것을 수학적으로 증명했습니다. 이 한 권의 책이 AI 업계에 첫 번째 겨울을 불러왔습니다. 연구 자금이 끊겼고, 많은 연구자들이 다른 분야로 떠났습니다.
부활은 1986년에 찾아왔습니다. 루멜하트(Rumelhart), 힌튼(Hinton), 윌리엄스(Williams)가 역전파(Backpropagation) 알고리즘을 학계 표준으로 정립하면서 다층 신경망의 가능성이 열렸습니다. 역전파는 출력층에서 시작해 거슬러 올라가며 모든 층의 가중치를 동시에 조정하는 방식으로, 이전까지 해결하지 못했던 다층 구조의 학습 문제를 풀어냈습니다. 이와 함께 "AI는 뇌처럼 분산 표현을 한다"는 프레임이 학계에 본격적으로 자리 잡기 시작했습니다.
그러나 이때 이미 내부에서 회의론이 제기됩니다. 1989년 DNA 이중나선 구조의 공동 발견자인 프랜시스 크릭(Francis Crick)은 네이처에 기고한 글에서 역전파를 포함한 인공신경망이 생물학적으로 비현실적이라고 지적했습니다. 이 역전파 방식은 현재의 LLM에서도 그대로 쓰이고 있는 학습 메커니즘입니다. 흥미롭게도 역전파 부활을 이끈 당사자인 힌튼 본인도 2023년 인터뷰에서 "역전파는 뇌가 사용하지 않는 방식"이라고 명시적으로 인정했습니다.
두 번째 겨울이 왔다가 다시 부활한 것은 2012년입니다. 힌튼 연구실의 알렉스넷(AlexNet)이 이미지 인식 대회 ImageNet에서 압도적인 성능으로 우승하면서 딥러닝 시대의 문이 열렸습니다. 알렉스넷이 사용한 합성곱 신경망(CNN)은 1962년 허블(Hubel)과 비셀(Wiesel)의 신경생리학 연구 — 고양이 시각피질이 단순한 선에서 모서리, 형태로 위계적 인식을 한다는 발견, 이 연구는 1981년 노벨상으로 이어집니다 — 에서 영감을 받은 것입니다. 그러나 영감을 받았다는 것이 곧 동일한 원리라는 뜻은 아닙니다. CNN의 수학적 구조는 실제 시각피질의 연산과 본질적으로 다르며, CNN을 잘 설계한다고 해서 시각피질의 작동 원리를 이해하게 되는 것도 아닙니다.
내러티브를 버리고 탄생한 모델 — 트랜스포머의 등장
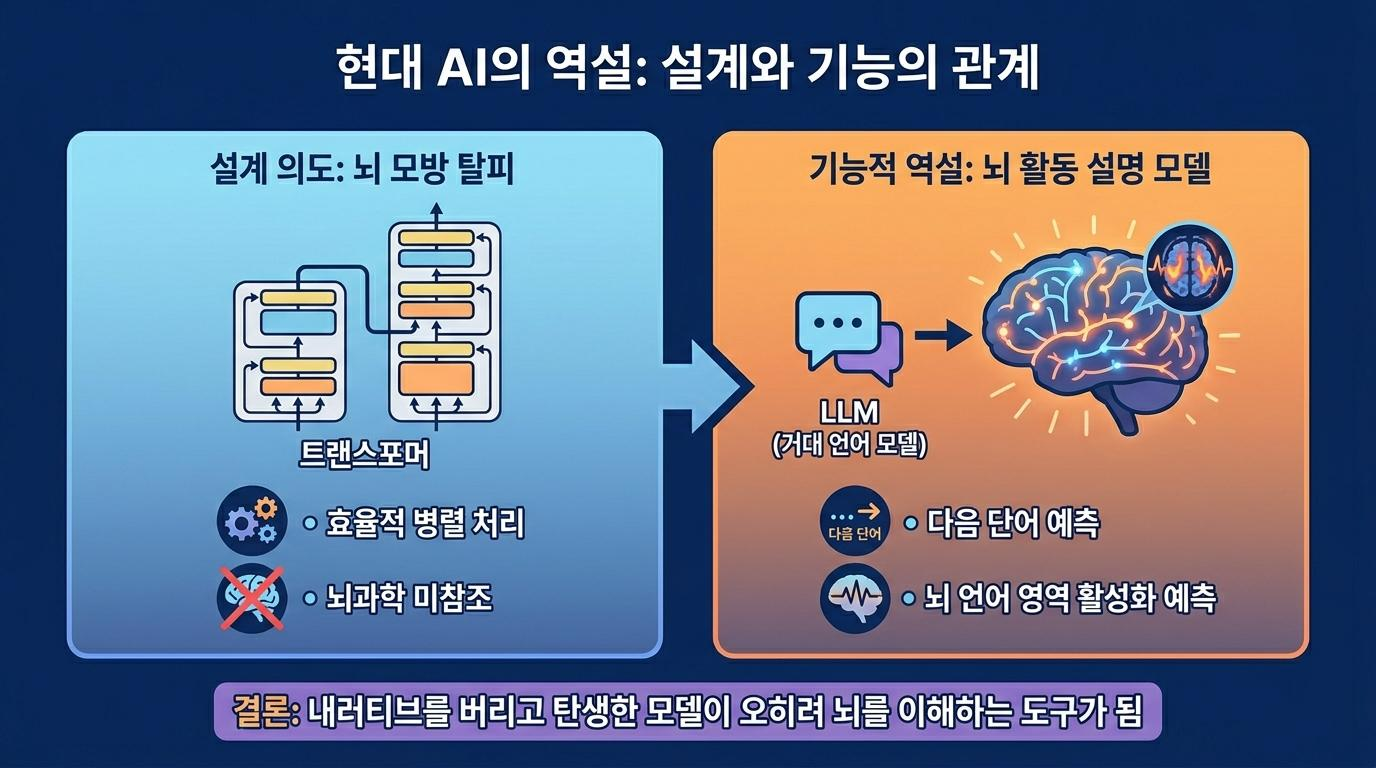
2017년 구글은 "Attention is All You Need"라는 제목의 논문을 발표했습니다. 현재 모든 최신 AI의 기반이 되는 트랜스포머(Transformer) 아키텍처가 처음 세상에 나온 순간입니다. 이 논문에는 뇌과학 관련 인용이 단 한 건도 없습니다. 논문의 목적은 뇌를 모방하는 것이 아니라, 기존의 순환 신경망(RNN)이 가진 순차 처리 방식의 비효율을 해결하는 것이었습니다.
트랜스포머의 핵심은 '어텐션(Attention)' 메커니즘입니다. 문장 안의 모든 단어가 서로를 동시에 참조하며 다음에 올 단어를 예측하는 구조로, RNN처럼 단어를 하나씩 순차적으로 처리할 필요 없이 병렬 처리가 가능합니다. 이것이 현재 대규모 언어 모델(LLM, Large Language Model)의 핵심 구조입니다. 그리고 이 구조가 언어를 넘어 이미지, 음성, 비디오, 단백질 구조 예측에 이르기까지 거의 모든 종류의 데이터에 적용 가능하다는 사실이 이후 밝혀지면서, 60년간 AI 업계를 지배했던 '분야별 최적 모델'이라는 가정이 무너졌습니다. 이미지에는 CNN, 언어에는 RNN이라는 구분이 뇌 모방 내러티브가 만들어낸 잘못된 제약이었던 것입니다.
스탠퍼드 대학의 HAI(인간중심 AI 연구소) 보고서에 따르면, 2024년 전 세계 민간 AI 투자 규모는 역대 최고인 2,523억 달러에 달했으며, 이 중 생성형 AI에 대한 투자만 339억 달러로 2022년 대비 8배 이상 증가했습니다. 이 자본의 흐름 뒤에는 "AI가 인간처럼 생각하는 기계"라는 강력한 내러티브가 작동하고 있었습니다. 기술적 실체와 무관하게, 내러티브는 자본을 끌어당기고 그 자본이 다시 기술을 만들었습니다.
역전된 질문 — 이제는 뇌가 AI를 닮았는가
여기서 이야기는 예상치 못한 방향으로 전환됩니다. LLM이 기존과 차원이 다른 언어 능력을 보여주기 시작하자, 뇌과학자들은 전혀 다른 질문을 던지기 시작했습니다. "AI가 뇌를 모방한 것이 아니라, LLM이 오히려 뇌의 언어 처리 방식을 설명하는 가장 좋은 모델일 수 있지 않을까?"
2021년 MIT 페도렌코(Fedorenko) 연구팀은 PNAS에 발표한 논문에서 43개의 언어 모델을 비교 분석했습니다. 각 모델이 인간 뇌의 언어 처리 영역 활성화 패턴을 얼마나 잘 예측하는지를 fMRI 데이터로 측정한 결과, 다음 단어 예측 성능이 뛰어난 모델일수록 인간 뇌의 반응도 더 정확히 예측한다는 사실이 드러났습니다. 트랜스포머 기반 모델인 GPT-2가 1위를 차지했습니다.
같은 시기 프린스턴 대학 하슨(Hasson) 연구팀이 구글 리서치와 협업해 2022년 네이처 뉴로사이언스에 발표한 연구는 더 직접적입니다. 9명의 피험자 뇌에 전극을 삽입하고 30분 분량의 팟캐스트를 들려주며 실시간 뇌 신호를 측정했더니, 뇌가 단어가 발화되기 직전에 다음 단어를 예측하는 신호를 보낸다는 것이 실측됐습니다. LLM이 다음 토큰을 예측하는 방식과 구조적으로 닮아 있다는 것입니다.
2024년 Nature Human Behaviour에 발표된 연구에서는 이 관계가 더욱 정교하게 검증됩니다. 연구팀은 'BrainBench'라는 신경과학 결과 예측 벤치마크를 만들고 LLM의 예측 성능을 전문가 집단과 비교했는데, LLM이 신경과학 실험 결과 예측에서 인간 전문가를 능가한다는 결과가 나왔습니다. 뇌과학 문헌으로 미세 조정된 BrainGPT 모델은 더욱 높은 성능을 보였습니다.
이것은 역설적인 반전입니다. 60년 동안 이어진 "AI는 뇌를 모방한다"는 내러티브가 틀렸다고 말하는 것이 아닙니다. 그 내러티브를 스스로 부수면서 탄생한 모델이 결국 뇌를 이해하는 가장 유효한 도구가 되었다는 것입니다. 모방을 목표로 삼지 않았던 모델이, 우연히 가장 정교한 뇌의 계산 모델이 된 셈입니다.
내러티브는 어떻게 기술과 자본을 움직이는가
이 60년의 역사에서 읽어야 할 핵심은 기술 그 자체가 아닙니다. 내러티브가 기술 발전의 방향과 자원 배분에 실질적으로 개입한다는 사실입니다. 매력적인 내러티브는 미디어를 끌어당기고, 미디어는 투자를 유인하며, 투자는 다시 더 강력한 내러티브를 생산합니다. 기술의 실체는 종종 이 루프 안에서 부차적인 것이 됩니다.
1958년 퍼셉트론의 등장이 그랬고, 1986년 역전파의 부활이 그랬으며, 2012년 딥러닝의 폭발이 그랬습니다. 그리고 2022년 ChatGPT의 출시 이후 지금까지 전 세계를 휩쓸고 있는 생성형 AI 열풍도 예외가 아닙니다. "AI가 곧 인간의 지능을 초월할 것"이라는 내러티브는 기술적 근거와 무관하게 수천억 달러의 자본을 움직이고, 정부의 정책을 바꾸고, 수백만 명의 커리어 선택에 영향을 미치고 있습니다.
그렇다면 이 내러티브를 단순히 과장되거나 잘못된 것으로 치부해야 할까요? AI 역사는 그 판단이 그리 단순하지 않음을 보여줍니다. 로젠블랫이 강조했던 뇌 모방 내러티브는 생물학적으로는 부정확했지만, 그 내러티브가 끌어들인 자원과 인재가 결국 LLM이라는 전혀 다른 경로로 의미 있는 결과를 만들어냈습니다. 내러티브는 진실이 아닐 수 있지만, 그렇다고 무의미하지도 않습니다. 그것은 자원과 방향을 조직하는 힘입니다.
중요한 것은 내러티브를 무비판적으로 수용하거나 전면 부정하는 양자택일이 아닙니다. 어떤 내러티브가 형성되고 있는지, 그것이 어떤 실체와 얼마나 접촉하고 있는지, 그리고 그 간극이 어느 지점에서 균열을 일으킬 것인지를 읽는 능력입니다. 시장에서 "이 기업의 주가는 거품이다"라는 말이 나올 때, 그것이 데이터 분석의 결론이라 해도 내러티브의 지속력을 무시한 분석은 절반짜리 분석에 불과합니다.
AI 담론을 읽는 새로운 시각
오늘날 한국 사회에서 AI를 둘러싼 논의는 여전히 "인간의 뇌를 닮은 기계"라는 프레임에 크게 기대고 있습니다. 딥러닝과 LLM은 종종 구분 없이 사용되고, 트랜스포머 아키텍처와 신경망의 근본적인 차이는 주목받지 못합니다. 이것은 단순한 개념적 혼동이 아닙니다. 어떤 AI 기술이 어떤 문제를 풀 수 있고, 어디에 투자할 가치가 있으며, 어떤 규제가 필요한지를 판단하는 사회적 역량과 직결됩니다.
현대의 LLM은 뇌를 모방해서 만든 기계가 아닙니다. 그러나 지금 이 시점에서 인간 뇌의 언어 처리를 가장 잘 설명하는 계산 모델이기도 합니다. 이 두 문장이 동시에 참일 수 있다는 것, 그리고 그 사이의 긴장과 간극이 오히려 우리가 주목해야 할 지점이라는 것이 60년 AI 역사가 남긴 가장 중요한 교훈입니다.
내러티브는 기술의 장식이 아닙니다. 그것은 기술이 어디로 가는지를 결정하는, 가장 눈에 띄지 않는 가장 강력한 변수입니다.




댓글 (0)
댓글 쓰기